
|
|
Projektbeschreibung
-
Methode
-
Schematische Illustration der Projektschritte
-
Genutzte korpuslinguistische Ressourcen, Daten und Verfahren
-
Entstehende Ressourcen
-
Kooperationen
-
Durchführende Forschungseinrichtungen und Ansprechpartner
-
Projektrelevante Publikationen
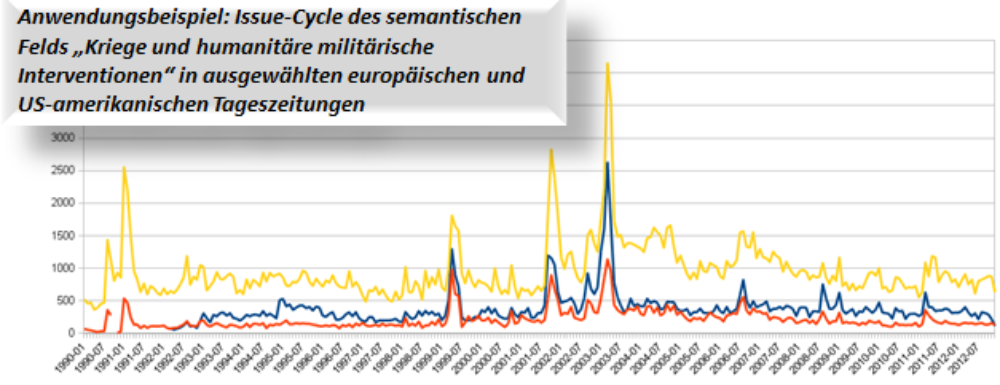
Wie mobilisieren internationale Akteure in Krisensituationen kollektive Identitäten? Spielen sie ethnische, religiöse, nationale, europäische, u.a. Bindungen gegeneinander aus? Welche Ursachenund Effekte hat diese Identitätspolitik? Das Projekt untersucht die internationale Diskussion über Kriege und humanitäre Interventionen seit dem Ende des Kalten Krieges. Es greift auf ein bereinigtes mehrsprachiges Korpus von mehreren hunderttausend Zeitungsartikeln aus der Qualitätstagespresse mehrerer europäischer Länder (A, D, Irland, F, UK) und den USA zurück (kontinuierlich erhobener Untersuchungszeitraum: Januar 1990 - Dezember 2011).
Sprachtechnologische Werkzeuge werden genutzt, um die Vielschichtigkeit der zu untersuchenden Indikatoren und den erheblichen Korpusumfang zu bewältigen. Der Forschungsverbund entwickelt Lösungen zur Überwindung bestehender Barrieren für den Einsatz computer- und korpuslinguistischer Verfahren.
1. Aus der Sicht der Computer- und Korpuslinguistik betreten wir Neuland, indem wir einen transparenten, individuell nutzbaren Complex Concept Builder entwickeln, mit dem komplexe Fachbegriffe für die Anwendung an alltagssprachlichem Textmaterial in einem interaktiven Verfahren operationalisiert werden. Der Complex Concept Builder integriert Tools zur Analyse der Beziehungen und Bewertungen, die Sprecher hinsichtlich ihrer kollektiven Identitäten äußern.
2. Die im Rahmen des Projekts entwickelten Analysewerkzeuge können darüber hinaus von der sozialwissenschaftlichen Community für eine breite Palette korpusanalytischer Anwendungen genutzt werden, einschließlich der Erfassung und semi-automatischen Kodierung von large-n Textsamples. Eine Explorationswerkbank zur Korpuserstellung und -erschließung wird auch über das Projektende hinaus als flexibles Bindeglied zu vorhandenen Infrastrukturen dienen.
Methode
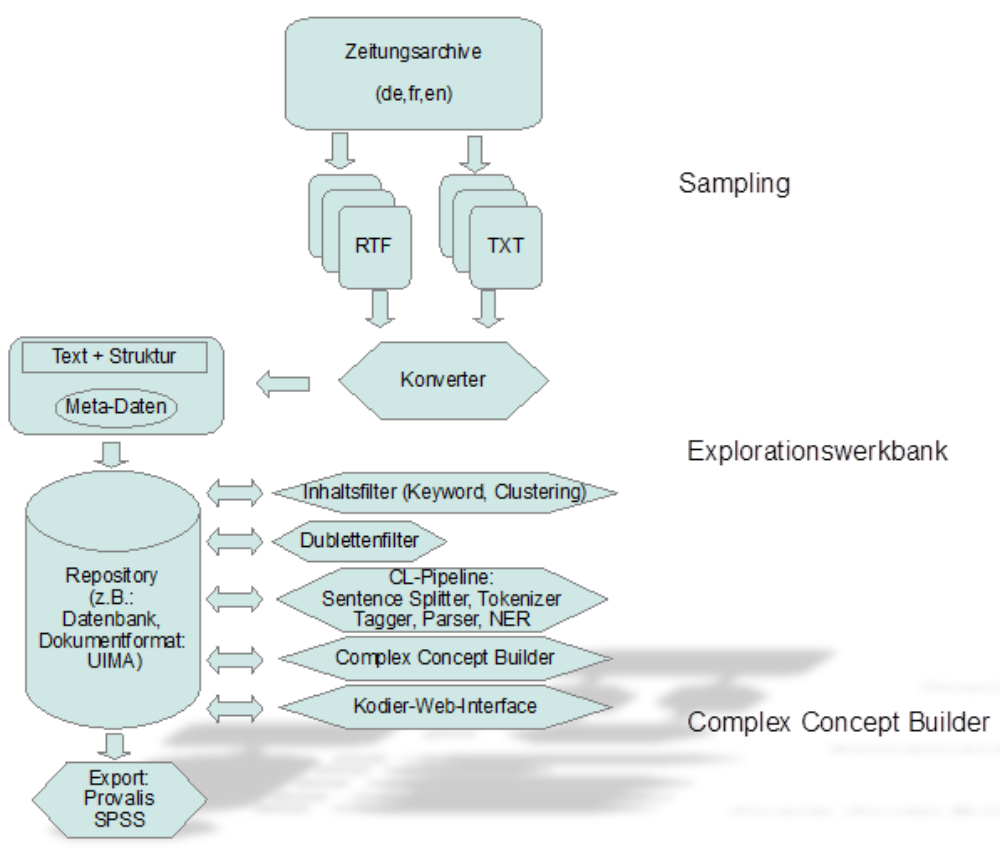
Um der Vielschichtigkeit der im Korpusmaterial zu untersuchenden Indikatoren ebenso Rechnung zu tragen wie dem erheblichen Korpusumfang und dem Nebeneinander von deutsch-, englisch- und französischsprachigen Texten, wird die Analyse sprachtechnologische Werkzeuge und Methoden nutzen, die in den Sozialwissenschaften bislang nur in Ausnahmefällen Anwendung fanden. Es erstellt dazu einen mehrsprachigen Korpus, der den Zeitraum von 1990 bis 2012 abdeckt. Dieser Korpus wird in einem arbeitsteiligen Verfahren zunächst bereinigt und danach mit einer Anzahl neu entwickelter automatischer sowie semi-automatischer Analysewerkzeuge codiert. Zu diesen Werkzeugen zählen insbesondere
- ein transparenter und lernfähiger Complex Concept Builder (CCB), mit dem komplexe fachwissenschaftliche Begriffe (wie der Identitätsbegriff inklusive der feinen Unterschiede und Nuancen zwischen verschiedenen kollektiven Identitäten) für die Anwendung an alltagssprachlichem Textmaterial operationalisiert werden können. Der CCB integriert zudem vorhandene Tools und aktuelle Methodenentwicklungen zur Analyse der Beziehungen und Bewertungen, die die Sprecher hinsichtlich verschiedener kollektiver Identitäten äußern.
- eine interaktive, web-basierte Explorationswerkbank zur Korpuserstellung, -erschließung und -kodierung (-annotation). Diese wird Sozialwissenschaftlern auch über das Projektende hinaus als flexibles Bindeglied zu vorhandenen Infrastrukturen (z.B. CLARIN) dienen. Die Werkbank lässt sich unterschiedlichsten individuellen Forschungsfragen und Textmaterialien anpassen und bildet insbesondere auch die technische Basis für den CCB.
Genutzte korpuslinguistische Ressourcen, Daten und Verfahren
Daten
In diesem Forschungsprojekt arbeiten wir mit einem nicht-öffentlich zugänglichen Korpus, der anhand von repräsentativen Keywords aus von öffentlichen Bibliotheken lizenzierten Volltextdatenbanken generiert wurde: ca. 1 Million Artikel aus Deutschland (FAZ, SZ), Österreich (Der Standard, Die Presse), Frankreich (Le Monde, Le Figaro), UK (The Guardian, The Times), Irland (The Irish Times, The Irish Independent), USA (New York Times, Washington Post).
Erprobte Verfahren
- Konvertierung und Metadatenanalyse der Textsamples
- Integration der Daten in ein Repository mit Web-Interface
- Dublettenanalyse (ngram Analyse)
- Indexierung der linguistischen Analysen (Postgres)
- Maschinelle Teilannotation mithilfe von Webservices aus CLARIN-D:
- Tokenisierung und Satzerkennung
- Part-of-Speech Tagging (TreeTagger, RFTagger, Bohnet-Pipeline)
- Lemmatisierung (TreeTagger, Bohnet-Pipeline, LemmaKorrektur)
- Dependenzparsing (Bohnet-Pipeline)
- Namenserkennung (Stanford-Pado)
Entstehende Ressourcen
Daten
Die externe Weiternutzung des Textkorpus ist nach derzeitigem Stand rechtlich nicht möglich.
Verfahren
- Aufbau einer integrierten Explorationsdatenbank, die anschließend für andere Anwendungen nutzbar ist und folgende Funktionen in einem Interface vereint:
- Konvertierung unterschiedlicher Quellformate, die
- Filterung von Dubletten und Semi-Dubletten in den Archiven
- Einbeziehung weiterer computerlinguistischer Konzepte und Werkzeuge (Wortart-Tagging, Parsing, Erkennung von Named Entities…)
- Konstruktion des Complex Concept Builder inkl. web-basierter Oberfläche:
- Keyword-basierte oder random-gesteuerte Exploration der Artikel
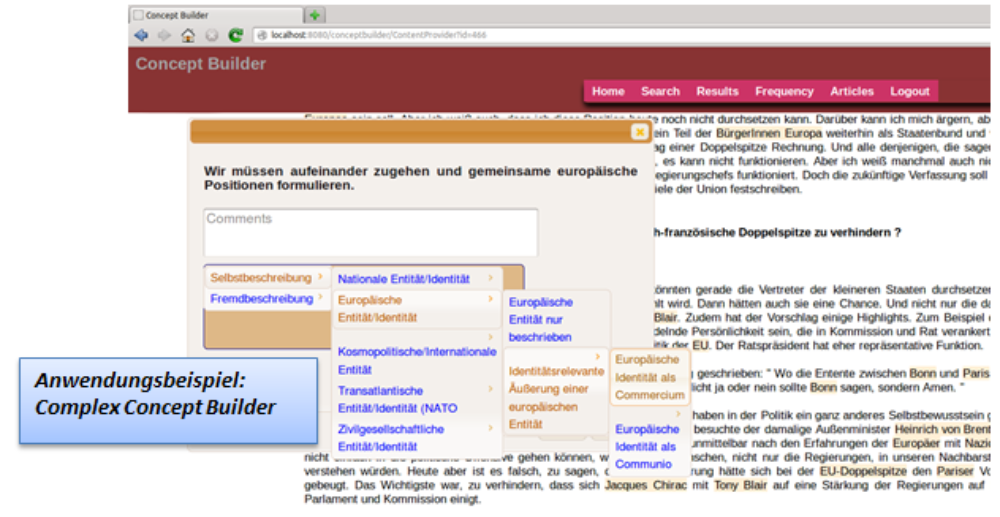

- Semi-automatische sowie lernfähige Annotation mit interaktivem, web-basierten Codierungsinterface (inkl. Annotator-Verwaltung)
- Integration von maschinellen Lernverfahren zur automatischen Erkennung von kollektiven Identitäten.
- Korpuslinguistische, semi-automatische Kodiermethodik für die Erforschung komplexer sozialwissenschaftlicher Fragestellungen
- Automatisches Themen-Clustering (Weiterentwicklung des Tools Dualist)
- Erprobung der automatischen Identifizierung komplexer linguistischer Strukturen: Sprecher, Redeformen, spezifische Sprechakte
- Integration der entstehenden Tools in CLARIN-D, insbesondere der Explorationsdatenbank und des CCB
Kooperationen
Teile der methodologischen und theoretischen Vorarbeiten basieren auf Ergebnissen vorheriger Projekte an der FU Berlin, die u.a. durch die Europäische Kommission im Rahmen der Forschungsinitiative RECON (Reconstituting Democracy in Europe) gefördert wurden.
Die im Verbundprojekt entwickelten Tools werden in die bestehenden eHumanities-Strukturen integriert, insbesondere im Rahmen des BMBF-geförderten Projekts CLARIN-D. Das IMS Stuttgart ist selbst als Infrastrukturzentrum in CLARIN integriert.
Durchführende Forschungseinrichtungen und Ansprechpartner
Universität Stuttgart, Institut für Sozialwissenschaften
- Leitung des Verbundprojekts und Verantwortung für die sozialwissenschaftlichen Fragestellungen
Prof. Dr. Cathleen Kantner
Institut für Sozialwissenschaften
Abteilung für Internationale Beziehungen und Europäische Integration
Breitscheidstr. 2, 70174 Stuttgart
Tel.: 0711-685-83425
Projektmitarbeiter:
PD Dr. Udo Tietz
Maximilian Overbeck
Universität Hildesheim, Institut für Informationswissenschaft und Sprachtechnologie,
Sprachtechnologie / Computerlinguistik
- Lexikalisch-terminologische Fragestellungen, „klassische“ Sentiment-Analyse
Prof. Dr. Ulrich Heid
Marienburger Platz 22, 31141 Hildesheim
Tel. 05121-883-832
heid@uni-hildesheim.de
Projektmitarbeiter:
Fritz Kliche
Universität Stuttgart, Institut für Maschinelle Sprachverarbeitung
- Multilinguale syntaktisch-strukturelle Analyse, maschinelle Lernverfahren
Prof. Dr. Jonas Kuhn
Pfaffenwaldring 5B, 70569 Stuttgart
Tel. 0711-685-81365
jonas@ims.uni-stuttgart.de
Projektmitarbeiter:
André Blessing
Universität Potsdam, EB Kognitionswissenschaften, Angewandte Computerlinguistik
- Illokutionäre Analyse, pragmatisch geprägte Sentiment-Analyse
Prof. Dr. Manfred Stede
Karl-Liebknecht-Str. 24-25, 14476 Golm.
Tel. 0331-977-2691
stede@uni-potsdam.de
Website des Projektpartners
Projektmitarbeiter:
Jonathan Sonntag
Projektrelevante Publikationen
2021
- Overbeck, Max (2021): Die Rückkehr der Religion in die politische Öffentlichkeit: Eine korpusanalytische Untersuchung religiöser Frames in westlichen Mediendebatten über bewaffnete Konflikte nach dem Ende des Kalten Krieges (1990-2012), Tectum Verlag.
2020
- Nothofer, Iris (2020): Verblendete Öffentlichkeiten. Blinde Flecken in der Debatte über humanitäre militärische Interventionen, Weilerswist: Velbrück Wissenschaft.
- Khalilpour, Golareh (2020): Western Conceptions of Democracy and the Transatlantic Divide over Democracy Promotion. Media Debates in the Context of Military Intervention, Baden-Baden: Nomos.
- Kantner, Cathleen; Overbeck, Max (2020): Exploring Soft Concepts with Hard Corpus-Analytic Methods, in: Nils Reiter, Axel Pichler, und Jonas Kuhn (Hrsg.), Reflektierte algorithmische Textanalyse. Interdisziplinäre(s) Arbeiten in der CRETA-Werkstatt, Berlin: De Gruyter (Reflektierte algorithmische Textanalyse. Interdisziplinäre(s) Arbeiten in der CRETA-Werkstatt), S. 128–141.
2018
- Overbeck, Max (2018): Vom Beobachter zum Teilnehmer: Europäische Mediendiskurse über Religion in bewaffneten Konflikten, in: Holger Zapf, Oliver Hidalgo, und Philipp W. Hildmann (Hrsg.), Das Narrativ von der Rückkehr der Religionen, Wiesbaden: Springer Fachmedien Wiesbaden (Das Narrativ von der Rückkehr der Religionen), S. 231–260.
- Kantner, Cathleen; Overbeck, Maximilian (2018): Die Analyse „weicher” Konzepte mit „harten” korpuslinguistischen Methoden., in: Andreas Blaette, Joachim Behnke, Kai-Uwe Schnapp, u. a. (Hrsg.), Computational Social Science: Die Analyse von Big Data, Baden-Baden: Nomos Verlag (Computational Social Science: Die Analyse von Big Data), S. 163–189.
2017
- Overbeck, Maximilian; Jerusalem Harry S. Truman Research Institute for the Advancement of Peace (Hrsg.) (2017): Shifting Perspectives on Religion and Armed Conflict in Western News Coverage,.
2016
- Kantner, Cathleen (2016): War and Intervention in the Transnational Public Sphere, UACES Contemporary European Studies, London and New York: Routledge (UACES Contemporary European Studies).
- Kantner, Cathleen; Overbeck, Maximilian (2016): Religiöse Identitäten als Diskursblocker, in: Ines-Jacqueline Werkner und Oliver Hidalgo (Hrsg.), Religiöse Identitäten in politischen Konflikten, Wiesbaden: VS Verlag (Religiöse Identitäten in politischen Konflikten), S. 173–191.
- Kantner, Cathleen; Kuhn, Jonas; Blessing, Andre; u. a. (2016): Die Anwendung computer- und korpuslinguistischer Methoden für eine interaktive und flexible Tiefenanalyse der Mobilisierung kollektiver Identitäten in öffentlichen Debatten über Krieg und Frieden - e-Identity, in: Jahrestagung der Digital Humanities im deutschsprachigen Raum (DHd), (Jahrestagung der Digital Humanities im deutschsprachigen Raum (DHd)).
- Heyer, Gerhard; Kantner, Cathleen; Niekler, Andreas; u. a. (2016): Modeling the dynamics of domain specific terminology in diachronic corpora, in: Proceedings of the 12th International conference on Terminology and Knowledge Engineering (TKE 2016), (Proceedings of the 12th International conference on Terminology and Knowledge Engineering (TKE 2016)).
2015
- Tietz, Udo; Kantner, Cathleen; Overbeck, Maximilian (2015): Multiple collective identities. The emergence of a new field of research in the social sciences. Introduction, in: The Tocqueville Revue / La Revue Tocqueville, (The Tocqueville Revue / La Revue Tocqueville), Jg. XXXVI, Nr. 2, S. 23–26.
- Sangar, Eric (2015): From “memory wars” to shared identities: Conceptualizing the transnationalisation of collective memory, in: The Tocqueville Review / La revue Tocqueville, (The Tocqueville Review / La revue Tocqueville), Jg. XXXVI, Nr. 2, S. 95–124.
- Overbeck, Maximilian (2015): Religion und religiöse Überzeugungen im 21. Jahrhundert. Ein Literaturbericht, in: Berliner Debatte Initial, (Berliner Debatte Initial), Jg. 26, Nr. 2, S. 123–131.
- Overbeck, Maximilian (2015): Post-secular or Post-religious? The Presence of Religion in Western Public Debates on Wars and Military Interventions,.
- Overbeck, Maximilian (2015): Observers turning into participants: Shifting perspectives on religion and armed conflict in Western news coverage, in: The Tocqueville Review/La revue Tocqueville, (The Tocqueville Review/La revue Tocqueville), Jg. XXXVI, Nr. 2, S. 95–124.
- Overbeck, Maximilian (2015): Die Rückkehr der Religion in die politische Öffentlichkeit? Eine computerlinguistische Exploration der deutschen Presse von 1946-2012, in: Matthias Lemke und Gregor Wiedemann (Hrsg.), Text-Mining in den Sozialwissenschaften. Grundlagen und Anwendungen zwischen qualitativer und quantitativer Diskursanalyse., Wiesbaden: VS Verlag (Text-Mining in den Sozialwissenschaften. Grundlagen und Anwendungen zwischen qualitativer und quantitativer Diskursanalyse.), S. 343–367.
- Overbeck, M. (2015): European Debates During The Lampedusa Crisis 2011: Europe At Odds?,.
- Kliche, F.; Schmidt, N.; Heid, U. (2015): Ein Wizard für die Erschließung roher Textdaten, in: Poster präsentiert auf der 2. Jahrestagung der Digital Humanities im deutschsprachigen Raum (DHd-2015), Universität Graz, (Poster präsentiert auf der 2. Jahrestagung der Digital Humanities im deutschsprachigen Raum (DHd-2015), Universität Graz).
- Kantner, Cathleen (2015): National media as transnational discourse arenas: The case of humanitarian military interventions, in: Thomas Risse (Hrsg.), European Public Spheres: Politics Is Back, Cambridge, UK: Cambridge University Press (European Public Spheres: Politics Is Back), S. 84–107.
- Kantner, Cathleen; Tietz, Udo (2015): L’intégration rationnelle des communautés a l’aune de la modernité, in: The Tocqueville Revue / La Revue Tocqueville, (The Tocqueville Revue / La Revue Tocqueville), Jg. XXXVI, Nr. 2, S. 27–49.
- Blessing, Andre; Kliche, Fritz; Heid, Ulrich; u. a. (2015): Computerlinguistische Werkzeuge zur Erschließung und Exploration großer Textsammlungen aus der Perspektive fachspezifischer Theorie, in: Zeitschrift für digitale Geisteswissenschaften, (Zeitschrift für digitale Geisteswissenschaften), Jg. Sonderband 1.
2014
- Tietz, Udo; Kantner, Cathleen (2014): Staatskritik und Antiinstitutionalismus bei Nietzsche und Marx, in: Steffen Dietzsch und Claudia Terne (Hrsg.), Nietzsches Perspektiven. Denken und Dichten in der Moderne, Berlin: De Gruyter (Nietzsches Perspektiven. Denken und Dichten in der Moderne), S. 133–162.
- Sonntag, Jonathan; Stede, Manfred (2014): Sentiment Analysis: What’s Your Opinion?, in: Chris Biemann und Alexander Mehler (Hrsg.), Text Mining, Springer (Text Mining), S. 177–199.
- Sonntag, Jonathan; Stede, Manfred (2014): GraPAT: a Tool for Graph Annotations., in: Nicoletta Calzolari, Khalid Choukri, Thierry Declerck, u. a. (Hrsg.), LREC, European Language Resources Association (ELRA) (LREC), S. 4147–4151.
- Sangar, Eric (2014): The Weight of the Past(s): The Impact of the Bundeswehr’s Use of Historical Experience on Strategy-Making in Afghanistan, in: Journal of Strategic Studies, (Journal of Strategic Studies), Jg. 38, Nr. 4, S. 411–444.
- Sangar, Eric; Douglas, Nadja (2014): Les relations armées-société en Allemagne, in: La Lettre de l’IRSEM, (La Lettre de l’IRSEM), Jg. 2014, Nr. 1, S. 6–9.
- Sangar, Eric (2014): Illuminating the shadow of the past: The transnationalisation of collective memory and is impact on debating foreign policy crises,.
- Sangar, Eric (2014): Die Bundeswehr in Afghanistan. Grenzen einer erfundenen Tradition, in: Michael Draxner (Hrsg.), Deutschland in Afghanistan, Oldenburg: BIS-Verlag (Deutschland in Afghanistan), S. 115–138.
- Ruppenhofer, Josef; Struß, Julia Maria; Sonntag, Jonathan; u. a. (2014): IGGSA-STEPS: Shared Task on Source and Target Extraction from Political Speeches., in: Journal for Language Technology and Computational Linguistics, (Journal for Language Technology and Computational Linguistics), Jg. 29, Nr. 1, S. 33–46.
- Ruppenhofer, Josef; Klinger, Roman; Struß, Julia Maria; u. a. (2014): IGGSA Shared Tasks on German Sentiment Analysis, in: Gertrud Faaß und Josef Ruppenhofer (Hrsg.), Workshop Proceedings of the 12th Edition of the KONVENS Conference, Hildesheim, Germany: University of Hildesheim (Workshop Proceedings of the 12th Edition of the KONVENS Conference).
- Overbeck, Maximilian; Kantner, Cathleen; Sangar, Eric (2014): The practical challenges of exploring “soft” concepts through “hard” methods: The corpus-linguistic analysis of multiple collective identities in contemporary transnational media debates,.
- Overbeck, Maximilian (2014): Religion resurrected? The Presence of Religion in European Public Debates on Wars and Military Interventions,.
- Overbeck, Maximilian (2014): Making a security identity from below? Transnational discourses in European media during the Libya crisis,.
- Overbeck, Maximilian (2014): European debates during the Libya crisis of 2011: shared identity, divergent action, in: European Security, (European Security), Jg. 23, Nr. 4, S. 583–600.
- Kantner, Cathleen (2014): The European public sphere and the debate about humanitarian military interventions, in: European Security, (European Security), Jg. 23, Nr. 4, S. 409–429.
- Heid, Ulrich; Kantner, Cathleen; Kuhn, Jonas; u. a. (2014): e-Identity - Erschließung und Exploration von Textdaten in den Sozialwissenschaften, in: Poster der Stuttgarter Projektpartner zum Gesamtprojekt, präsentiert auf dem DH-Summit 2015, (Poster der Stuttgarter Projektpartner zum Gesamtprojekt, präsentiert auf dem DH-Summit 2015).
- Asr, Fatemeh Torabi; Sonntag, Jonathan; Grishina, Yulia; u. a. (2014): Conceptual and Practical Steps in Event Coreference Analysis of Large-scale Data., in: Teruko Mitamura, Eduard H. Hovy, und Martha Palmer (Hrsg.), EVENTS@ACL, Association for Computational Linguistics (EVENTS@ACL), S. 35–44.
2013
- Sidorenko, Wladimir; Sonntag, Jonathan; Krüger, Nina; u. a. (2013): From newspaper to microblogging: What does it take to find opinions?, in: Alexandra Balahur, Erik Van der Goot, und Andrés Montoyo (Hrsg.), WASSA@NAACL-HLT, The Association for Computer Linguistics (WASSA@NAACL-HLT), S. 81–86.
- Sangar, Eric (2013): Historical Experience. Burden or Bonus in Today’s Wars? The British Army and the Bundeswehr in Afghanistan, Freiburg: Rombach Verlag.
- Kantner, Cathleen; Tietz, Udo (2013): Identitäten und multiple Identitäten. Über die wertrationale Integration der Gemeinschaften unter den Bedingungen der Moderne, in: Erhard Crome und Udo Tietz (Hrsg.), Dialektik - Arbeit - Gesellschaft. Festschrift für Peter Ruben, Potsdam: WeltTrends (Dialektik - Arbeit - Gesellschaft. Festschrift für Peter Ruben), S. 47–63.
- Blessing, André; Sonntag, Jonathan; Kliche, Fritz; u. a. (2013): Towards a Tool for Interactive Concept Building for Large Scale Analysis in the Humanities., in: Piroska Lendvai und Kalliopi Zervanou (Hrsg.), LaTeCH@ACL, The Association for Computer Linguistics (LaTeCH@ACL), S. 55–64.
2012
- Kutter, Amelie; Kantner, Cathleen (2012): Corpus-Based Content Analysis: A Method for Investigating News Coverage on War and Intervention, in: International Relations Online Working Paper Series, (International Relations Online Working Paper Series), Jg. 2012, Nr. 1.
- Blessing, André; Stegmann, Jens; Kuhn, Jonas (2012): SOA meets Relation Extraction: Less may be more in Interaction, in: Proceedings of the Workshop on Service-oriented Architectures (SOAs) for the Humanities: Solutions and Impacts, (Proceedings of the Workshop on Service-oriented Architectures (SOAs) for the Humanities: Solutions and Impacts), S. 6–11.
- Blessing, André; Schütze, Hinrich (2012): Crosslingual distant supervision for extracting relations of different complexity., in: Xue wen Chen, Guy Lebanon, Haixun Wang, u. a. (Hrsg.), CIKM, ACM (CIKM), S. 1123–1132.
- Al Khatib, Khalid; Schütze, Hinrich; Kantner, Cathleen (2012): Automatic Detection of Point of View Differences in Wikipedia, in: Proceedings of the 24th International Conference on Computational Linguistics, Mumbai, India: COLING ’12 (Proceedings of the 24th International Conference on Computational Linguistics), S. 33–49.
2011
- Wüest, Bruno; Clematide, Simon; Bünzli, Alexandra; u. a. (2011): Semi-Automatic Core Sentence Analysis: Improving Content Analysis for Electoral Campaign Research, in: International Relations Online Working Paper Series, (International Relations Online Working Paper Series), Jg. 2011, Nr. 1.
- Kantner, Cathleen; Kutter, Amelie; Hildebrandt, Andreas; u. a. (2011): How to get rid of the Noise in the Corpus: Cleaning Large Samples of Digital Newspaper Texts, (Report) Stuttgart University, doi: http://www.uni-stuttgart.de/soz/ib/forschung/IRWorkingPapers/IROWP_Series_2011_2_Kantner_Kutter_Analysis_Newspaper_Texts.pdf.
- Kantner, Cathleen (2011): European Identity as Commercium and Communio in Transnational Debates on Wars and Humanitarian Military Interventions, in: RECON Online Working Papers, (RECON Online Working Papers), Jg. 37.
- Kantner, Cathleen (2011): Debating Humanitarian Military Interventions in the European Public Sphere, in: RECON Online Working Papers, (RECON Online Working Papers), Jg. 30.
- Cap, Fabienne; Heid, Ulrich (2011): Distinguishing Specialised Discourse: The Example of Juridical Texts on Industrial Property Rights and Trademark Legislation, in: International Relations Online Working Paper Series, (International Relations Online Working Paper Series), Jg. 2011, Nr. 3.
2010
- Kantner, Cathleen (2010): L’identité européenne entre commercium et communio, in: Laurence Kaufmann und Danny Trom (Hrsg.), Qu’est-ce qu’un collectif? Du commun à la politique, Paris: Éditions de l’École des Hautes Ètudes en Sciences Sociales (EHESS) (Qu’est-ce qu’un collectif? Du commun à la politique), S. 221–247.
2009
- Kolb, Peter; Kutter, Amelie; Kantner, Cathleen; u. a. (2009): Computer- und korpuslinguistische Verfahren für die Analyse massenmedialer politischer Kommunikation: Humanitäre und militärische Interventionen im Spiegel der Presse, in: Wolfgang Hoeppner (Hrsg.), Technischer Bericht Nr. 2009-01. GSCL-Symposium Sprachtechnologie und eHumanities, Duisburg: Universität Duisburg-Essen (Technischer Bericht Nr. 2009-01. GSCL-Symposium Sprachtechnologie und eHumanities), S. 62–71.
2006
- Kantner, Cathleen (2006): Collective identity as shared ethical self-understanding: The case of the emerging European identity, in: European Journal of Social Theory, (European Journal of Social Theory,), Jg. 9, Nr. 4, S. 501–523.

Cathleen Kantner
Prof. Dr.Leitung Sowi III